Koneoppimisen käytön aloittaminen CSC:llä
Tämä opas on osa koneoppimisopastamme.
Sinulla on Pythonilla kirjoitettua koneoppimiskoodia, joka toimii kannettavallasi, mutta se on todella hidasta. Olet kuullut, että siirtyminen GPU:ihin ja CSC:n supertietokoneisiin voisi olla ratkaisu, mutta dokumentaatio vaikuttaa hieman vaikeaselkoiselta.
CSC:n laskentaympäristö on hyvin dokumentoitu osoitteessa docs.csc.fi, mutta aloittelijalle voi olla hieman vaikeaa tietää, mistä aloittaa. Tässä oppaassa näytetään vaihe vaiheelta, miten saat koodisi ja datasi Puhdin supertietokoneelle ja ajettua GPU:illa. Se on osa koneoppimisopastamme.
CSC:llä on useita supertietokoneita: Puhti, Mahti ja LUMI. Tässä oppaassa keskitymme Puhdin käyttöön, koska siellä on laajin ohjelmistovalikoima ja selainkäyttöliittymä, mikä tekee käytön aloittamisesta erittäin helppoa.
Kun siirrät koodiasi kannettavalta tietokoneeltasi Puhdin supertietokoneelle, on tärkeää ymmärtää, että Puhti ei ole vain "nopeampi kannettava". Mittakaavan perustavanlaatuisen eron vuoksi jotkin asiat toimivat supertietokoneessa hyvin eri tavalla. Varaudu siis siihen, että joudut ottamaan askeleen taaksepäin ja opettelemaan uudelleen joitakin laskennan toimintatapoja. Mielestämme tämä on kohtuullinen hinta siitä, että saat käyttöösi Suomen tehokkaimman tutkijoille tarkoitetun GPU-resurssin!
Note
Vaikka tässä oppaassa pyritään selittämään jokainen vaihe huolellisesti, suosittelemme silti, että sinulla on vähintään perustason tuntemus Linuxin komentorivistä, sillä muutamassa vaiheessa sitä täytyy käyttää. Voit esimerkiksi tutustua Linux-perusteet-oppaamme ensimmäiseen osioon.
Vaihe 1: Hanki CSC-käyttäjätunnus
Ensimmäiseksi tarvitset CSC-käyttäjätunnuksen, jos sinulla ei vielä ole sellaista. Jos työskentelet tai opiskelet suomalaisessa yliopistossa, siirry MyCSC-portaaliin osoitteessa my.csc.fi ja napsauta "Get Started". Valitse Haka-kirjautuminen ja oma yliopistosi pudotusvalikosta. Tämän jälkeen sinun pitäisi pystyä kirjautumaan sisään tavallisilla yliopistotunnuksillasi. Täytä tietosi Sign up -sivulla. Kun olet valmis, sinun pitäisi saada vahvistussähköposti.
Lisätietoja ja erityistapauksia löydät erillisestä dokumentaatiostamme "How to create new user account".
Vaihe 2: Liity olemassa olevaan projektiin tai luo uusi
Toiseksi sinun täytyy kuulua laskentaprojektiin. Tämä johtuu siitä, että CSC:n on seurattava, miten resurssejamme käytetään, ja laskentaprojektit ovat siihen käytettävä mekanismi.
Jos kuulut tutkimusryhmään, kysy professoriltasi tai ryhmäsi vetäjältä, onko teillä jo CSC-projekti, johon voit liittyä. Jos näin on, projektin johtaja (todennäköisesti professori) voi lisätä sinut projektiin MyCSC-portaalissa. Katso tarkemmat ohjeet dokumentaatiostamme uuden käyttäjän lisäämisestä projektiin
Muussa tapauksessa, esimerkiksi jos työskentelet oman väitöskirjaprojektisi parissa, voit luoda oman projektin. Luo uusi projekti siirtymällä My CSC:hen ja kirjautumalla sisään kuten yllä vaiheessa 1. Valitse My Projects ja napsauta New project -painiketta. Anna projektille nimi ja kuvaile lyhyesti tekemääsi tutkimusta. "Academic" on useimmissa tapauksissa todennäköisesti sopiva kategoria. Lisätietoja löydät dokumentaatiostamme "Creating a new project".
Kun projektisi on luotu, sinun täytyy myös lisätä projektiisi käyttöoikeus Puhtiin. Katso lisätietoja kohdasta palvelun käyttöoikeuden lisääminen projektille.
Kirjoita muistiin projektin unix-ryhmä, joka on tyypillisesti jotakin muotoa
project_2001234. Tässä dokumentissa käytämme jatkossa
project_2001234-merkintää paikkamerkkinä aina, kun viittaamme projektin unix-ryhmään,
mutta muista aina korvata se omalla projektinumerollasi.
Vaihe 3: Kirjaudu Puhtiin
Puhtiin on monia tapoja päästä käsiksi. Perinteinen tapa on käyttää SSH-asiakasohjelmaa, joka tarjoaa pelkästään tekstipohjaisen komentoriviyhteyden Puhdissa toimivaan Linux-järjestelmään. Tässä kuitenkin suosittelemme Puhdin selainkäyttöliittymää, johon pääsee verkkoselaimella osoitteessa puhti.csc.fi. Kirjaudu sisään tämän oppaan vaiheessa 1 luodulla käyttäjätunnuksella ja salasanalla.
Note
Jos olet juuri luonut tunnuksesi muutama minuutti sitten, sitä ei ehkä ole vielä aktivoitu Puhdissa. Käy hakemassa kahvia tai muuta haluamaasi juotavaa ja yritä uudelleen muutaman minuutin kuluttua! ☕
Kirjautumisen jälkeen näet Puhdin selainkäyttöliittymän, joka näyttää suunnilleen tältä:
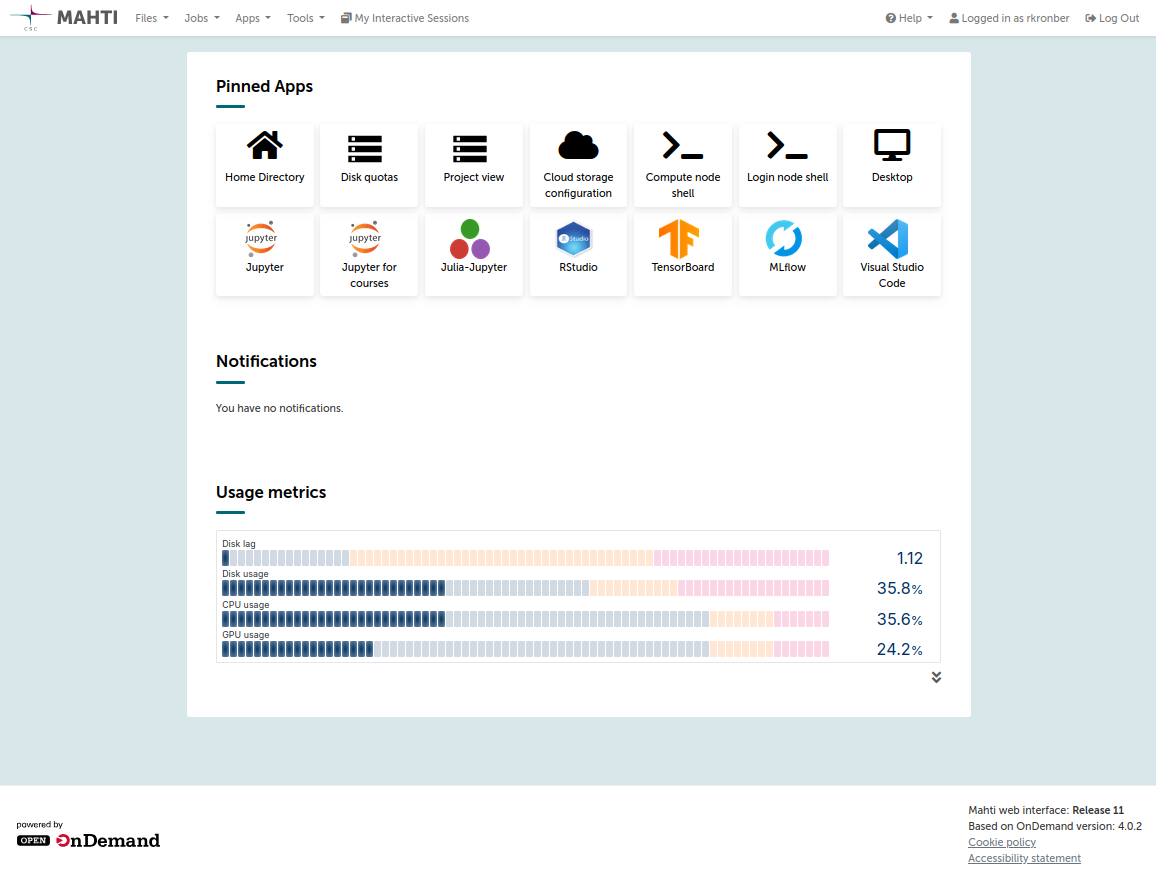
Jos Puhdin selainkäyttöliittymä (joka perustuu Open OnDemandiin) ei ole sinulle tuttu, käytä hetki sen toimintojen tutustumiseen.
Tällä hetkellä tärkeimmät tarkistettavat asiat ovat:
-
Files-valikko, jossa pitäisi näkyä useita levyalueita käyttöösi: henkilökohtainen Home directory sekä
projappl- jascratch-hakemistot jokaiselle projektillesi. -
Tools → Login node shell, jolla voit käynnistää päätesession Puhdissa. Täältä voit suorittaa Linux-komentoja.
Vaihe 4: Kopioi koodisi Puhtiin
On suositeltavaa säilyttää koodisi sen projektin projappl-hakemistossa,
johon koodisi kuuluu, esimerkiksi /projappl/project_2001234/. Voit siirtyä tähän
sijaintiin Puhdin selainkäyttöliittymän tiedostoselaimessa.
Jos sinulla on koodia omalla tietokoneellasi, yksi vaihtoehto on käyttää tiedostoselaimen oikeassa yläkulmassa olevaa "Upload"-painiketta datan lataamiseen palveluun.
Meidän tapauksessamme kloonaamme koodin GitHub-repositoriosta, ja sitä varten meidän täytyy avata päätesessio. Napsauta tiedostoselaimessa "Open in Terminal" tai käynnistä Login node shell Tools-valikosta. Kirjoita sitten seuraavat komennot (ja paina ENTER jokaisen rivin lopuksi):
cd /projappl/project_2001234 # needed only if your didn't navigate to correct directory
git clone https://github.com/mvsjober/pytorch-cifar10-example
Tämän pitäisi luoda kopio annetun GitHub-repositorion koodista Puhdin levylle. Voit nyt siirtyä vastaluotuun hakemistoon joko päätteestä tai tiedostoselaimen kautta.
Note
Tässä olemme tarjonneet esimerkkikoodia yksinkertaisen neuroverkon opettamiseen CIFAR10-datalla. Voit tietenkin korvata sen omalla koodillasi, esimerkiksi omalta tietokoneeltasi.
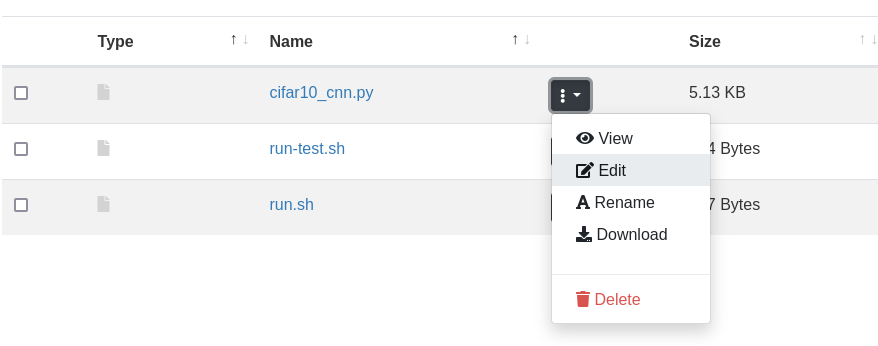
Tiedostoselaimessa voit tarkastella tiedostoa napsauttamalla sitä. Tarkista erityisesti
päälähdekoodi tiedostossa cifar10_cnn.py. Tiedoston loppupuolella näet
komentorivivalinnat. Huomaa, että --data_path on pakollinen valinta:
se on polku siihen sijaintiin, johon aineisto on tallennettu.
Tiedostoselaimessa voit muokata tiedostoa napsauttamalla tiedostokohtaista valikkoa (kolme pistettä) ja valitsemalla Edit, kuten alla on esitetty.
Vaihe 5: Kopioi datasi Puhtiin
On suositeltavaa säilyttää opetusdata projektin scratch-hakemistossa,
esimerkiksi /scratch/project_2001234/. Muista, että scratch-hakemisto
siivotaan säännöllisesti, joten älä säilytä siellä mitään tärkeää. Aineistoilla
tulisi yleensä olla jokin pysyvämpi sijainti, kuten
Allas säilytystä varten projektin elinkaaren ajan.
Voit siirtyä kohtaan /scratch/project_2001234/ Puhdin selainkäyttöliittymän
Files-selaimessa. Tässä haemme aineiston julkisesta Allas-ämpäristä komennolla wget.
Komentoa wget voidaan käyttää minkä tahansa URL-osoitteen omaavan tiedoston lataamiseen.
Kirjoita komento aineiston lataamiseksi (avaa pääte kuten vaiheessa 4, jos et ole jo tehnyt niin):
cd /scratch/project_2001234 # needed only if your didn't navigate to correct directory
wget https://a3s.fi/mldata/cifar-10-python.tar.gz
Ladattu tiedosto on CIFAR10-aineiston pakattu arkisto Python-ystävällisessä muodossa.
Seuraavaksi voisit purkaa arkiston, mutta tässä esimerkissä olemme päättäneet olla tekemättä niin. Sen sijaan puramme tiedostot nopealle paikalliselle levylle jokaisen ajon alussa. Tästä lisää seuraavassa osiossa.
Vaihe 6: Tarkista, mitä Python-kirjastoja tarvitset
Ennen kuin ajat koodisi, sinun kannattaa tarkistaa, mitä Python-kehyksiä tai
-kirjastoja tarvitset. Jos käytät Internetistä lataamaasi koodia, mukana on yleensä
asennusohjeita tai requirements.txt-tiedosto, joka kertoo, mitä Python-kirjastoja
tarvitaan. Muista, että usein asennusohjeita ei pidä noudattaa täsmälleen sellaisinaan,
koska niissä oletetaan usein, että asennat ohjelmistoa henkilökohtaiselle tietokoneelle.
CSC tarjoaa monia valmiiksi asennettuja Python-ympäristöjä suosittuja kehyksiä ja kirjastoja varten. Niitä kannattaa yleensä käyttää lähtökohtana, vaikka ne eivät sisältäisikään kaikkia tarvitsemiasi paketteja. Katso luettelo CSC:n supertietokoneilla tarjotuista data-analytiikan ja koneoppimisen moduuleista.
Esimerkiksi PyTorchilla ja
TensorFlow’lla on omat erilliset moduulinsa, kun taas
Python Data on yleinen moduuli, joka sisältää monia
data-analytiikan kirjastoja, kuten numpy, SciPy, Scikit-learn, Dask, JupyterLab
ja monia muita. Nämä ohjelmistoympäristöt voidaan aktivoida komennolla module
load. Katso yllä luetelluilta dokumentaatiosivuilta tarkemmat tiedot.
Jos löydät moduulin, jossa on suurin osa tarvitsemastasi, mutta muutama paketti puuttuu,
voit asentaa ne helposti itse (kotihakemistoosi) komennolla
pip install --user. Katso lisätietoja Python-dokumentaatiostamme siitä,
miten voit asentaa paketteja
itse.
Jos ohjelmistotarpeesi ovat monimutkaisempia eikä niitä ole helppo kattaa olemassa olevilla moduuleillamme, on aina mahdollista luoda omia Python-ympäristöjäsi. Jos et ole varma, mitä tehdä, voit aina ottaa yhteyttä asiakastukeemme.
Vaihe 7: Luo ensimmäinen eräajon komentotiedosto
Puhti on supertietokoneklusteri, mikä tarkoittaa, että se on satojen tietokoneiden kokonaisuus. Sen sijaan, että ohjelmia ajettaisiin suoraan, ne asetetaan jonoon ja ajoitusjärjestelmä (nimeltään "Slurm") päättää, milloin ja missä ohjelma suoritetaan.
Jotta voimme ajaa ohjelman Slurmissa, meidän täytyy määritellä eräajon komentotiedosto. Tämä on vain tekstitiedosto, joka sisältää joukon Slurm-valintoja määrittelemään ohjelmalle tarvitsemamme resurssit sekä varsinaiset komennot ohjelman suorittamiseen. Voit lukea lisää eräajon komentotiedostojen määrittelystä erilliseltä dokumentaatiosivultamme.
Tiedostosta run-cifar10.sh koodihakemistossamme löydät esimerkin
eräajon komentotiedostosta:
#!/bin/bash
#SBATCH --account=project_2001234
#SBATCH --partition=gputest
#SBATCH --nodes=1
#SBATCH --ntasks=1
#SBATCH --cpus-per-task=10
#SBATCH --mem=32G
#SBATCH --time=15
#SBATCH --gres=gpu:v100:1,nvme:10
module purge
module load pytorch
tar xf /scratch/project_2001234/cifar-10-python.tar.gz -C $LOCAL_SCRATCH
srun python3 cifar10_cnn.py --data_path=$LOCAL_SCRATCH/cifar-10-batches-py
Tämä ajaa työn gputest-osiossa käyttäen 10 CPU-ydintä, 32 Gt muistia
ja yhtä NVIDIA V100 GPU:ta. Työn enimmäiskesto on 15 minuuttia. Itse asiassa 15
minuuttia on pisin ajoaika, jonka voit pyytää gputest-osiossa, koska se on tarkoitettu
vain lyhyisiin testiajoihin. Lopuksi gres-valinnan teksti nvme:10
pyytää 10 Gt nopeaa paikallista levyä (nimeltään "NVMe").
#SBATCH-valintojen alapuolella näet varsinaiset komennot. Komentotiedostomme tekee
kolme asiaa:
- Lataa
pytorch-moduulin (ja poistaa ensin kaikki muut aiemmin ladatut moduulit) - Purkaa CIFAR10-aineiston scratch-levyltä löytyvästä arkistosta nopealle
paikalliselle levylle. Nopean paikallisen levyn polku löytyy
$LOCAL_SCRATCH-ympäristömuuttujasta. Scratch-levyn polku vaihtelee projektin nimen mukaan, joten sinun täytyy muokata komentotiedostoa ja asettaa oikea polku omaa tapaustasi varten. - Lopuksi se ajaa varsinaisen Python-komentotiedoston ja antaa datan
tallennuspolun
--data_path-argumentissa. Huomaa, että data sijaitsee nyt nopealla paikallisella levyllä.
Note
Sinun ei tarvitse käyttää nopeaa paikallista NVMe-levyä kuten tässä esimerkissä, mutta se on hyvä käytäntö, koska suuren tiedostomäärän lukeminen jaetusta tiedostojärjestelmästä (kuten scratchista ja projapplista) voi heikentää suorituskykyä, ja äärimmäisissä tapauksissa heikentää kaikkien käyttäjien suorituskykyä. Lue lisää tiedostojärjestelmän tehokkaasta käytöstä koneoppimisoppaastamme.
Vaihe 8: Aja ensimmäinen testityösi
Jotta voit ajaa komentotiedoston eli välittää sen Slurm-jonoon, suorita komento (koodihakemistosta):
Jos lähetys onnistui, sen pitäisi ilmoittaa jotakin tämän kaltaista:
Jos näet sen sijaan virheilmoituksen, katso yleisten eräajovirheiden sivumme. Jos et löydä ratkaisua sieltä, älä epäröi ottaa yhteyttä asiakastukeemme.
Voit tarkistaa käynnissä olevan työsi joko päätteestä:
tai Puhdin selainkäyttöliittymän valikosta Jobs → Active Jobs.
Vaihe 9: Tarkista työn tuloste
Kun työ on valmistunut, sen tulosteen pitäisi ilmestyä tiedostoon, jonka nimi on
jotakin tyyliin slurm-12345678.out, missä numero on työsi eräajon tunniste
(joka tulostettiin lähetyksen yhteydessä). Voit tarkastella tätä tiedostoa
napsauttamalla sitä tiedostoselaimessa tai käyttämällä komentorivillä esimerkiksi
komentoa less (poistu less-ohjelmasta painamalla 'q').
Kun olet varmistunut siitä, että työ toimii kuten pitääkin, voit ajaa sen varsinaisessa
gpu-osiossa, joka sallii yli 15 minuutin työt. Muokkaa vain tiedostoa
run-cifar10.sh, vaihda osioksi gpu ja lähetä työ uudelleen.
Huomaa, että voit lähettää monta työtä samaan aikaan, esimerkiksi eri parametreilla. Älä kuitenkaan lähetä satoja töitä samanaikaisesti.
Vaihe 10: Lisälukemista ja avun saaminen
Nyt kun olet päässyt alkuun, saatat olla kiinnostunut tutustumaan muuhun dokumentaatioomme. Esimerkiksi:
- Ajojen suorittaminen Slurmilla
- Sovellukset Puhdissa ja Mahdissa, erityisesti PyTorch ja TensorFlow.
- CSC:n koneoppimisopas
Jos sinulla on kysyttävää tästä oppaasta tai muita ongelmia koneoppimisen käytön aloittamisessa CSC:n palveluissa, älä epäröi ottaa yhteyttä asiakastukeemme.