Mahtia koskevat tekniset tiedot
Mahtin käytöstäpoisto syksyllä 2026
Mahti poistetaan käytöstä vaiheittain, ja sen korvaa Roihu, CSC:n seuraavan sukupolven supertietokone, joka tarjoaa paremman suorituskyvyn ja laajemmat ominaisuudet.
Mahtin laskentapalvelut suljetaan 31. elokuuta 2026 klo 12.00 EEST. Tallennustilan ja kirjautumissolmujen on suunniteltu pysyvän käytettävissä 15. lokakuuta 2026 puoleenpäivään asti, mutta käyttäjiä kehotetaan vahvasti siirtämään kaikki tarvitsemansa data järjestelmästä pois elokuun 2026 loppuun mennessä.
Laskentasolmut
Mahtissa on yhteensä 1404 CPU-solmua ja 24 GPU-solmua. CPU-solmujen teoreettinen huippusuorituskyky on 7,5 petaflopsia ja GPU-solmujen 2,0 petaflopsia, yhteensä 9,5 petaflopsia.
Sekä CPU- että GPU-solmuissa on kaksi AMD Rome 7H12 -suoritinta, joissa on 64 ydintä kummassakin, mikä tekee ytimien kokonaismäärästä noin 180 000. Suorittimet perustuvat AMD Zen 2 -arkkitehtuuriin, tukevat AVX2-vektorikäskykantaa ja toimivat 2,6 GHz:n perustaajuudella (maksimiboosti enintään 3,3 GHz). Suorittimet tukevat samanaikaista monisäikeistystä (SMT), jossa kukin ydin voi suorittaa kahta laitesäiettä. Kun SMT on käytössä, säikeiden kokonaismäärä solmua kohden on 256.
CPU-solmut on varustettu 256 Gt:n muistilla, ja valtaosassa niistä
ei ole paikallisia levyjä. Yhteensä 60 solmua on varustettu
paikallisella 3,8 Tt:n NVMe-asemalla. Ne ovat käytettävissä small- ja
interactive-osioissa.
GPU-solmut on varustettu 512 Gt:n muistilla ja paikallisella 3,8 Tt:n NVMe-asemalla. Niissä on myös neljä Nvidia Ampere A100 -GPU:ta. Osassa solmuista A100-GPU:t on jaettu useiksi pienemmiksi GPU:iksi, joilla on vain osa A100-GPU:iden laskenta- ja muistikapasiteetista. Ne ovat hyödyllisiä interaktiiviseen työskentelyyn, kursseille ja koodin kehittämiseen.
NUMA-kokoonpano
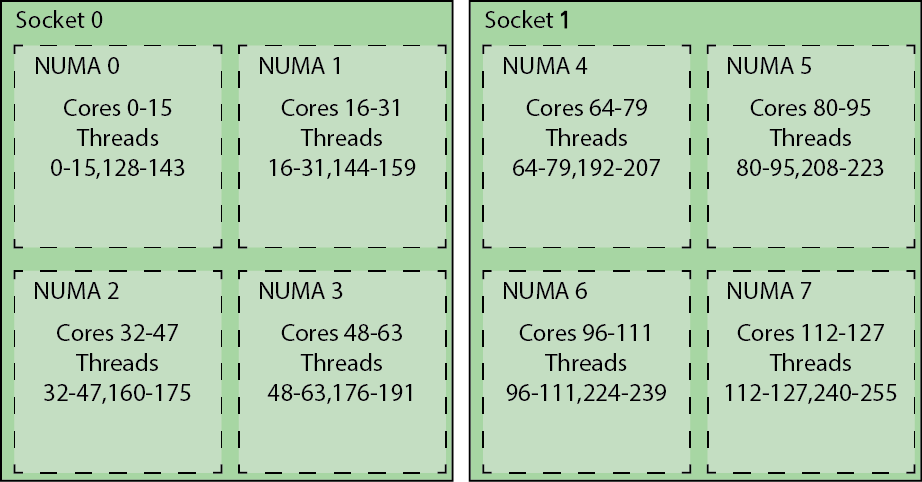
Mahti-solmulla on hyvin hierarkkinen rakenne. Solmussa on kaksi kantaa, joista kumpikin sisältää yhden suorittimen ja muistidimmit. Kaikki solmun muisti on jaettua, mutta muistin suorituskyky riippuu ytimen etäisyydestä muistiin. Hieman paremman muistisuorituskyvyn tarjoamiseksi ajamme kutakin suoritinta NPS4-tilassa (NUMA per socket 4), joka jakaa edelleen jokaisen suorittimen neljään NUMA-alueeseen. Jokaisessa NUMA-alueessa on 16 ydintä ja kaksi muistiohjainta sekä yhteensä 32 GiB muistia. Ydin 0 suorittaa säikeitä 0 ja 128, ydin 1 säikeitä 1 ja 129 ja niin edelleen. Alla oleva kuva näyttää, miten säikeet jakautuvat ytimille ja NUMA-solmuille.
Ytimet, ydinryhmät ja laskentapiirit
Suorittimen perusrakenneosa on ydin, jotka ryhmitellään ydinryhmiksi (CCX) ja edelleen laskentapiireiksi (CCD).
Jokaisessa ytimessä on 32 KiB L1-datavälimuistia ja 32 KiB L1-käskyvälimuistia. Myös L2-välimuisti on yksityinen ydinkohtaisesti, ja jokaisella ytimellä on 512 KiB L2-välimuistia. Jokaisessa ytimessä on kaksi FMA-yksikköä (fused multiply add), jotka toimivat täysillä 256-bittisillä vektoreilla, mikä tarkoittaa, että kummallakin yksiköllä voidaan suorittaa jokaisella kellosyklillä operaatioita 8 yksittäistarkkuuden liukuluvulle tai 4 kaksoistarkkuuden liukuluvulle. Siten parhaimmillaan 2 (multiply+add) x 2 (kaksi yksikköä) x 4 (vektorin leveys) = 16 kaksoistarkkuuden liukulukutoimitusta sykliä kohden.
Ytimestä seuraavalle tasolle siirryttäessä 4 ydintä ryhmitellään yhdeksi ydinryhmäksi (CCX), jossa ytimet jakavat saman 16 MiB:n L3-välimuistin. Kaksi tällaista CCX-osaa yhdistetään sitten muodostamaan laskentapiiri (CCD).
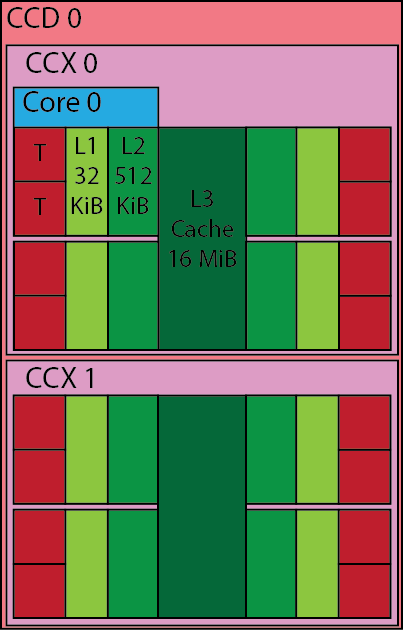
Jokainen suoritin koostuu 8 laskentapiiristä sekä erillisestä I/O-piiristä, jossa sijaitsevat muistiohjaimet ja PCI-e-ohjain. Jokainen solmu muodostuu sitten kahdesta tällaisesta suorittimesta ja yhdestä 200 gbit HDR -verkkosovittimesta.

Jos haluat perusteellisemman kuvauksen Zen 2 -ytimestä, voit lukea siitä lisää WikiChipissä
Verkko
Yhdysverkko perustuu Mellanox HDR InfiniBandiin, ja jokainen solmu on kytketty verkkoon yhdellä 200 Gbps HDR -linkillä. Verkon topologia on dragonfly+-topologia. Topologia koostuu useista solmuryhmistä, joista kukin on sisäisesti kytketty fat tree -topologialla, ja nämä fat tree -rakenteet on sitten kytketty toisiinsa all-to-all-linkeillä.
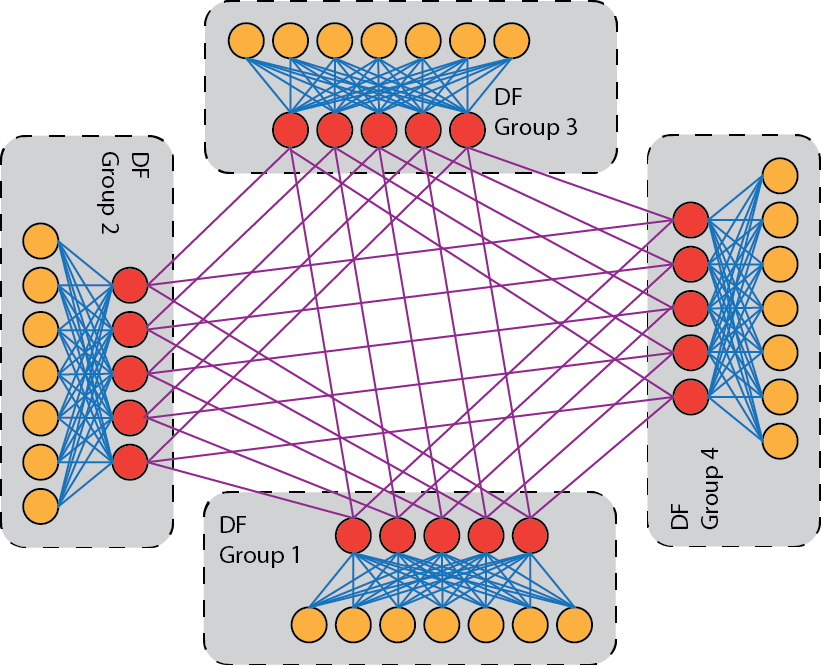
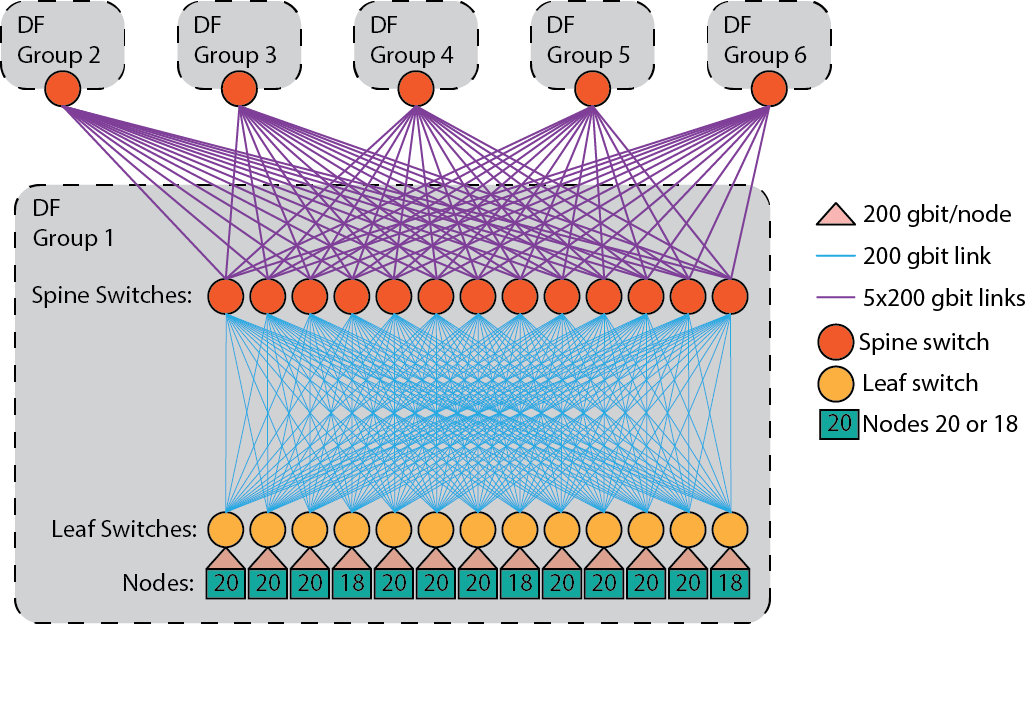
Mahtissa kussakin dragonfly-ryhmässä on 234 solmua, ja sisäisen fat tree -rakenteen ylivarauskerroin on 1,7:1. Lehtikytkimeen on kytketty 20 tai 18 solmua, ja jokaisessa lehtikytkimessä on 12 linkkiä ryhmän runkokytkimeen. Kaikki linkit ovat 200 Gbps:n linkkejä. Ryhmiä on yhteensä 6, ja ryhmien välillä on täysin estoton all-to-all-yhteys, jossa kustakin runkokytkimestä menee 5 kappaletta 200 Gbps:n linkkejä yhteen runkokytkimeen jokaisessa muussa ryhmässä.
Tallennus
Mahtissa on 8,7 Pt:n Lustre-rinnakkaistallennusjärjestelmä, joka tarjoaa tilaa koti, projekti ja scratch -tallennusalueille.
Mahtin nykyinen Lustre-kokoonpano on:
| Storage area | # OSTs | # MDTs |
|---|---|---|
| home | 8 | 1 |
| projappl | 8 | 1 |
| scratch | 24 | 2 |
Katso terminologia kohdasta Lustre-dokumentaatio.
Mahtin scratch voi tarjota paremman suorituskyvyn kuin muut tallennusalueet,
jos sovelluksesi ja datan koko ovat riittävän suuria, koska siinä on enemmän
OST- ja MDT-kohteita.
Mahtin I/O:n huippusuorituskyky on noin 100 Gt/s kirjoituksessa ja 115 Gt/s lukemisessa. Tämä suorituskyky saavutettiin kuitenkin varatulla järjestelmällä, jossa oli 64 laskentasolmua, mikä tarkoittaa noin 1,5 Gt/s laskentasolmua kohden. Jos käytetään enemmän solmuja tai monet työt tekevät merkittävästi I/O:ta, 1,5 Gt/s:n suorituskykyyn ei päästä. Näin on myös silloin, jos sovelluksen I/O-malli ei ole tehokas.