Kuinka skaalata replikoita automaattisesti ylös ja alas
Rahti mahdollistaa automaattisen horisontaalisen autoskaalauksen suorittimen ja muistin kulutuksen perusteella. Tämä tarkoittaa, että alusta voidaan määrittää lisäämään sovelluksesta enemmän kopioita (skaalaus ylöspäin), kun nykyiset kopiot kuluttavat liikaa suoritinta ja/tai muistia, sekä poistamaan sovelluksen kopioita (skaalaus alaspäin), kun suorittimen ja/tai muistin kulutus on liian vähäistä ja pienempi määrä kopioita riittää nykyiseen kuormaan.
Horisontaalinen/vertikaalinen skaalaus
Horisontaalinen skaalaus tarkoittaa, että sovelluksesta lisätään enemmän kopioita tai replikoita. Kubernetesissa tämä tarkoittaa useampia Podeja, joissa ajetaan samaa konttia samoilla parametreilla. Virtuaalikoneissa tämä tarkoittaa useampien virtuaalikoneiden lisäämistä samalla flavorilla ja levykuvalla.
Vertikaalinen skaalaus tarkoittaa, että nykyiseen kopioon lisätään enemmän resursseja. Kubernetesissa tämä tarkoittaa korkeampien suorittimen tai muistin rajojen asettamista. Virtuaalikoneissa se tarkoittaa koneen luomista uudelleen suuremmalla flavorilla, jossa on enemmän suoritinta tai muistia.
Tämän ilmeinen hyöty on se, että resurssien kulutusta voidaan optimoida automaattisesti ja dynaamisesti. Se pienentää sellaisen sovelluksen ylläpitokustannuksia, jolla on vain ajoittain suuri kuorma. Skaalauksen ylöspäin vasteaika on sekuntien luokkaa, ja oikein säädettynä se voi tarjota sovelluksen käyttäjille saumattoman käyttökokemuksen.
Määritys
Tätä varten tarvitsemme ensin Deploymentin. Mikä tahansa deployment toimii, mutta voit käyttää tätä esimerkkiä, joka ottaa käyttöön yksinkertaisen testisovelluksen:
Huom: Muista ensin kirjautua Rahtiin
echo "apiVersion: apps/v1
kind: Deployment
metadata:
name: example
spec:
selector:
matchLabels:
app: httpd
replicas: 4
template:
metadata:
labels:
app: httpd
spec:
containers:
- name: httpd
image: docker.io/lvarin/oom-killer
command:
- /app/app.py
- '10'
ports:
- containerPort: 8080
" | oc create -f -
Deploymentin pitäisi nyt käynnistää 4 kopiota samasta Podista. Määritämme myöhemmin sen pienentämään tai kasvattamaan Podien määrää resurssikulutuksen perusteella.
Lisää resurssirajat
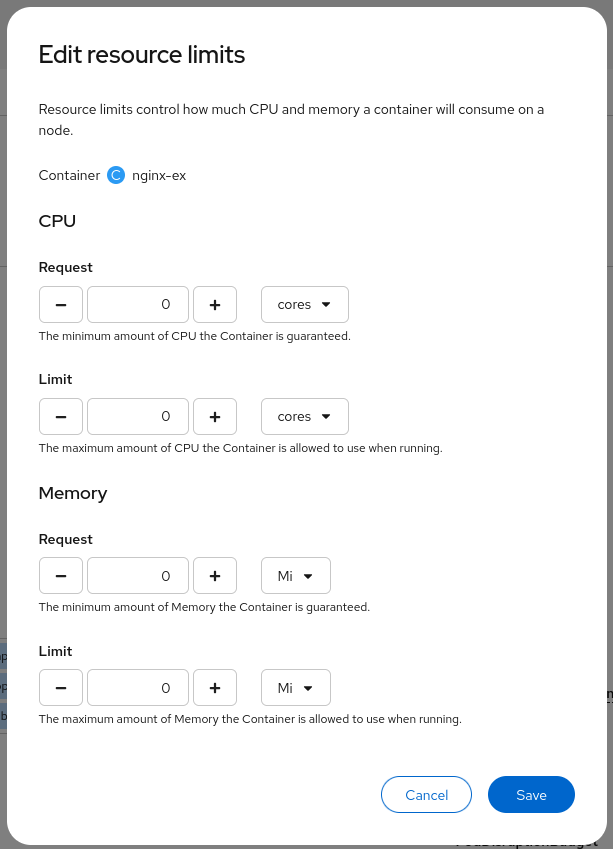
Seuraava vaihe on asettaa suorittimen ja muistin resurssirajat. Tämä on enimmäismäärä suoritinta ja muistia, jota kukin Pod voi käyttää. Siirry Deployment-sivulta kohtaan Actions > Edit resource limits
Sinun täytyy asettaa raja (Podia kohden) suorittimelle ja muistille. "Request"-kenttää ei ole pakko täyttää.
Tässä esimerkissä asetamme:
- suorittimen rajaksi
1. - muistin rajaksi
1Gi.
Lisää HorizontalAutoscaler
Kun Podien rajat on asetettu, voit nyt lisätä horisontaalisen autoskaalaajan. Siirry Deployment-sivulta kohtaan Actions > Add HorizontalPodAutoscaler.
Aseta ensin replikoiden enimmäis- ja vähimmäismäärä. Yleensä vähimmäismääräksi jätetään 1 ja enimmäismääräksi asetetaan arvo, joka vastaa kokonaiskiintiön "reilua osuutta". Jos sinulla on esimerkiksi yhteensä 20 Podin kiintiö ja yksi ainoa Deployment, enimmäismääräksi kannattaa asettaa 20, jotta koko käytettävissä oleva kiintiö voidaan hyödyntää. Mutta jos samassa nimiavaruudessa on kaksi deploymentia jakamassa kiintiötä, enimmäismääräksi kannattaa asettaa 10 kummallekin.
Kun vähimmäis- ja enimmäismäärä on asetettu, meidän täytyy määrittää resurssien käyttöprosentti, joka käynnistää skaalauksen ylöspäin. Jompikumpi tai molemmat resursseista (suoritin ja muisti) voidaan asettaa. Se, mikä raja ja mille resurssille asetetaan, riippuu ajamastasi sovelluksesta. Jotkin sovellukset kuormittavat enemmän suoritinta, jotkin muistia ja jotkin molempia. Käytännössä parametrien säätäminen on iteratiivinen prosessi.
Kun määritettyjen resurssien käyttö ylittää asetetun rajan, uusi replika luodaan. Esimerkiksi asetamme muistin käytöksi 50 % rajalla 1Gi. Kun muistin käyttö saavuttaa ja ylittää 500 Mt:n rajan, uusi replika luodaan, mikä kaksinkertaistaa käytettävissä olevan kokonaismuistin. Tämä skaalaus ylöspäin jatkuu niin kauan kuin kokonaismuistin käyttö on yli 50 % käytettävissä olevasta muistista.
Toisaalta skaalaus alaspäin tapahtuu, kun ylimääräistä kapasiteettia ei enää tarvita, eli kun yhden replikan poistamisen jälkeen käytetty kokonaismuisti ei ylitä 50 %:a skaalauksen alaspäin jälkeisestä käytettävissä olevasta kokonaismäärästä.
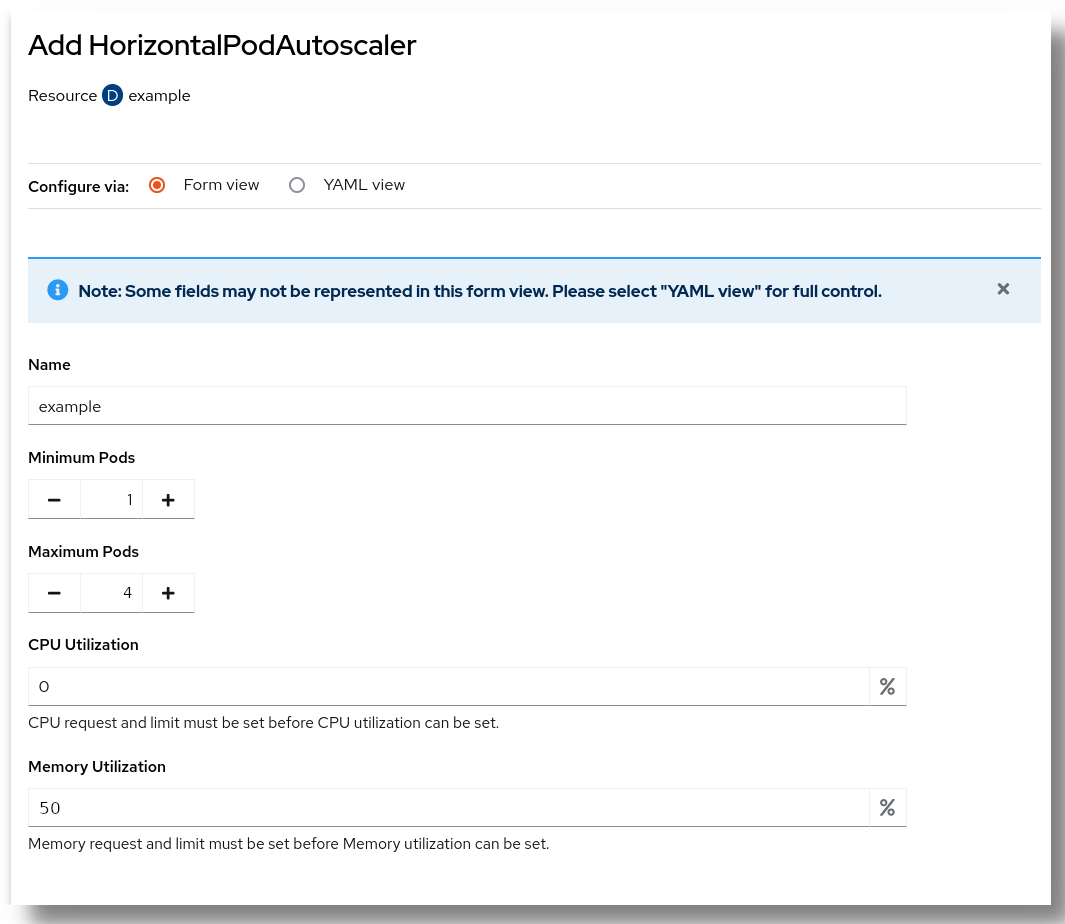
Tässä esimerkissä asetamme:
1Podien vähimmäismääräksi.4Podien enimmäismääräksi.50% muistin käyttöasteeksi.
Emme muuta suorittimen käyttöastetta.
Testaa ja seuraa
Muutaman minuutin kuluttua meillä pitäisi olla vain yksi Pod, jonka suorittimen käyttö on lähes nolla ja muistin käyttö 100 Mt. Autoskaalaaja odottaa jopa 10 minuuttia ennen Podien poistamista välttääkseen sahaamisen; lisätietoja on alla. Voit tarkistaa tämän Pods-sivulta (Project > Pods kehittäjän sivulla).

Komentorivin käyttö
Voit käyttää komentorivikäyttöliittymää autoskaalaajan nykyisen tilan tarkistamiseen:
Yksi Pod riittää, koska käytössä on vain noin 100 Mt 1 Gin kokonaismuistista. Tämä on vähemmän kuin määrittämämme 50 % muistista. Nostamme nyt muistin käyttöä keinotekoisesti. Avaamme päätteen ainoaan käynnissä olevaan Podiin (napsauta Podin nimeä ja sitten "Terminal"-välilehteä) ja suoritamme seuraavan komennon:
Pääte
Jos et näe komentoja päätteessä, laajenna sitä napsauttamalla oikeasta yläkulmasta "Expand". Voit myös pienentää sen takaisin, ja komennot näkyvät silti
Tämä luo uuden prosessin, joka varaa 5 kappaletta 100 Mt:n RAM-muistilohkoja. Koska 100 + 500 Mt on enemmän kuin 50 % 1 Gin kokonaismuistista, autoskaalaaja luo uuden Podin.
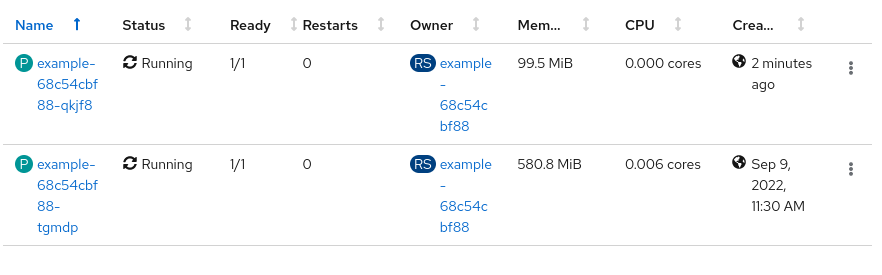
Seuraa tilannetta ja odota, että toinen Pod luodaan. Resursseja voidaan seurata projektin pääsivulta, joka antaa yleiskuvan koko projektista, mukaan lukien kiintiön käyttö. Vaihtoehtoisesti voit siirtyä luomamme deploymentin sivulle (Project-sivulta kohtaan Deployment, napsauta example ja lopuksi Metrics-välilehteä).
Tämän jälkeen voit tappaa luomasi prosessin ja nähdä, kuinka sovellusta skaalataan alaspäin poistamalla toinen Pod.
Skaalauksen alaspäin viive
Vaikka skaalaus ylöspäin on suunniteltu tapahtumaan mahdollisimman nopeasti, skaalaus alaspäin kestää jopa 10 minuuttia. Tämä johtuu vakautusikkunasta. Kubernetesin upstream-dokumentaation mukaan:
The stabilization window is used to restrict the flapping of replica count when the metrics used for scaling keep fluctuating. The autoscaling algorithm uses this window to infer a previous desired state and avoid unwanted changes to workload scale.