Creating, converting, uploading and sharing virtual machine images
This article explains how to manage images in Pouta.
Creating images
There are two different options for creating new virtual machine images: creating the image from scratch, and launching a virtual machine based on an existing image, making modifications on the running machine and saving the changes as a new image by creating a snapshot.
Creating an image based on an existing image
Launch a virtual machine using one of the available images either through the Horizon web interface or through the command line interface.
Launching an instance on the command line:
openstack server create --flavor <flavor> \
--image <image uuid> \
--key-name <key name> \
--nic net-id=<name of network> \
--security-group default \
--security-group <additional security group> <name of server>
Login and make any necessary changes. To ensure consistent snapshots, snapshots should only be created from instances which are powered off. First power off your instance:
Then create a snapshot of the machine's current state:
It takes some time to create the snapshot. Once it is finished, it appears as a new image. If you need the original instance, you can power it on after the snapshot has been created.
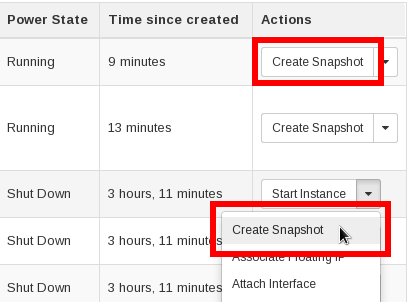
In the web UI under Compute | Instances, the instance-specific Create Snapshot menu items work for the same effect as the CLI command above. The snapshots created will appear in the Compute | Images section.
Creating an image from scratch
There are a number of tools for creating images from scratch. These tools can be categorized into tools that involve running an operating system in a virtual machine for setting up the image and tools that take a base image and make modifications to it without running a virtual machine. We will call these "installation-based tools" and "base image tools".
| Installation-based tools | Base image tools | |
|---|---|---|
| Pros |
|
|
| Cons |
|
|
| Examples | virt-install, virt-manager, VirtualBox | diskimage-builder, virt-builder |
The generic workflow when using installation-based tools:
- Obtain an installation media or a network installation link.
- Start a virtual machine and point it to the installation media or network installation link.
- Go through the installer.
- This step can optionally be automated using e.g. Kickstart.
- After the installation is finished, shut down the VM and use additional tools to prepare the image for cloud use.
The generic workflow when using base image tools:
- Optionally customize configuration files that are used to generate the final image.
- Determine the suitable customization parameters.
- Run a command to generate the final image.
You can get more information about creating images in the very thorough OpenStack virtual machine image guide. In particular, see the chapters on creating images manually and tool support for creating images.
Caveats to keep in mind when creating images from scratch
These caveats usually only need to be considered when using installation-based methods of image creation. The tools that use base images are usually specifically designed to create images for clouds, so they take care of these caveats for you. If you decide to use an installation-based method of image creation, you should look into the excellent virt-sysprep tool that takes care of most modifications necessary for cloud use with a single command line command. This chapter lists some of the caveats that need to be handled before an image is ready for clouds.
cloud-init
There is a tool called cloud-init that must be installed on any images that are to be used in Pouta clouds. It is used for certain tasks that need to be run when a virtual machine first boots up such as generating SSH host keys and adding user SSH public keys.
User accounts (can be done with virt-sysprep)
Cloud images should only have a minimal set of user accounts. Most likely, they should only have one regular generic user account (e.g. "cloud-user" on the default images provided by CSC) and the root user account.
SSH host keys (can be done with virt-sysprep)
Images used in the cloud must not contain any SSH host keys, as having them in the image would mean that every server launched using the image would have the same identity from the point of view of SSH. It is also a security risk, as anyone with access to the image file would be able to personate any server launched using that image file. Fresh SSH host keys need to be generated by cloud-init (see above) when a virtual machine first boots up.
Network interface ordering (can be done with virt-sysprep)
The udev device manager in the Linux kernel has a function that pins a specific network interface name to a specific MAC address. This is not good if several virtual machines are to be created from an image, as all virtual machines will have different MAC addresses. It is also not good if you create a snapshot out of a virtual machine and try to use that snapshot to launch a virtual machine, as it will remember the MAC address of the old virtual machine that was used to create the snapshot. The best way to do this is to use virt-sysprep.
Partitioning
When partitioning a Linux image, you should make sure the root partition is the first and only partition. During the virtual machine bootup process, OpenStack inserts SSH keys on the first partition under the /root/.ssh directory, which means this partition must be the root partition and not e.g. /boot. Logging in is not be possible without the root password unless the keys are correctly inserted.
ACPI daemon
The ACPI daemon is used to receive commands to manage the power state of a virtual machine. You should install an ACPI daemon on the machine images to allow proper power down/reboot in the cloud interface.
Hotplug
To be able to use volumes, you need to have ACPI hotplug enabled. This is on by default in CentOS 6 and newer, but for Ubuntu, you need to add the line "acpiphp" to /etc/modules. For other distros, please check how to load acpiphp on boot from the distro documentation.
Converting images
When performing a snapshot of a virtual machine, OpenStack creates an image in raw format. These images typically take as many GB as the capacity of the root disk of the virtual machine, regardless of the amount of GB actually used by the customer. As a result, taking snapshots can quickly deplete the space available for images.
A solution to this problem is to convert the image obtained from the snapshot to more compact formats, such as qcow2, which stores the customer data only. To do so, we download the raw image, we convert it to qcow2, and we upload the newly obtained image to OpenStack. Given that raw images can take many GB, we do not recommend performing this operation on a personal computer, but to use an auxiliary virtual machine within Pouta instead. In the following, we illustrate the procedure using a temporary virtual machine.
-
We assume we have just performed a snapshot of a virtual machine, and we have thus obtained an image myVmSnapshot. The first step is to create a temporary virtual machine that we will use to convert myVmSnapshot. The virtual machine should have enough space to host myVmSnapshot and its compact version at the same time. Since the compact version will be smaller or of equal size of myVmSnapshot, a safe choice is to select a flavor that is capable of hosting two times the size of myVmSnapshot. For example, if myVmSnapshot has a size of 80GB, a suitable flavor for the auxiliary virtual machine is io.160GB because it has 160 GB of ephemeral storage. The operating system can be
The only additional requirements for the setting up of the virtual machine are i) attaching a public floating IP, and ii) enabling SSH, so that we can actually log into the virtual machine.AlmaLinux-9, for example. -
Once the virtual machine is up and running, we copy the OpenStack RC File v3 for accessing to cPouta/ePouta in the virtual machine. If you do not have such file yet, please refer to this guide to obtain a copy.
Login into the virtual machine and use the file to load your credentials. -
In order to host the image obtained from the snapshot, we need to initialize properly the ephemeral storage. To do so, please refer to our guide. After this step, we assume the ephemeral disk is mounted in /mnt.
- Next, we need to equip the virtual machine with some basic tools we will need. We create a python-3 virtual environment, which we will use to interact with cPouta/ePouta, and we enter in it. Now we install the actual tools we need to talk with cPouta/ePouta.
- Next, we download the image we obtained taking the snapshot. Move to the ephemeral storage directory. Though it is not required, at this point we recommend opening a screen session, which allows to keep a process running in background, i.e., without the need of waiting for its completion before closing the terminal. We now issue the command to download the image obtained from the snapshot. Given the size of the image, the process will take few minutes. We can exit the screen session by pressing CTRL+A followed by CTRL+D. We can re-enter the screen session any time typing:
-
Once the previous command has finished, it is time to convert the image.
As previously mentioned, the qcow2 format will store only the actual customer data instead of storing a 1-to-1 copy of the root disk. If the size of the customer data is considerably smaller than the total capacity of the root disk, similarly the qcow2 image will be considerably smaller than the raw image. -
Once the conversion is completed, the new image can be uploaded to OpenStack.
If the operation is successful, we can remove the image in raw format from OpenStack. We may keep the auxiliary virtual machine for future image conversions, or delete it right after its usage.
Uploading images
You can upload images either using the web interface or the openstack command line tool.
Before uploading, you need to know what format the image you are uploading is. The most likely options are qcow2 and raw. You can find out the type of the image using the file command. This is what a qcow2 image looks like:
$ file images/Ubuntu-15.10-Phoronix.qcow2
images/Ubuntu-15.10-Phoronix.qcow2: Qemu Image, Format: Qcow (v3), 10737418240 bytes
And this is what a raw image looks like:
$ file images/Ubuntu-14.04-old.raw
images/Ubuntu-14.04-old.raw: x86 boot sector; partition 1: ID=0x83, active, starthead 0, startsector 16065, 20948760 sectors, code offset 0x63
Upload using the command line:
openstack image create --disk-format <disk format> --private --file <image file to upload> <name of image to create>
This should upload the image. It takes a while before the image is usable.
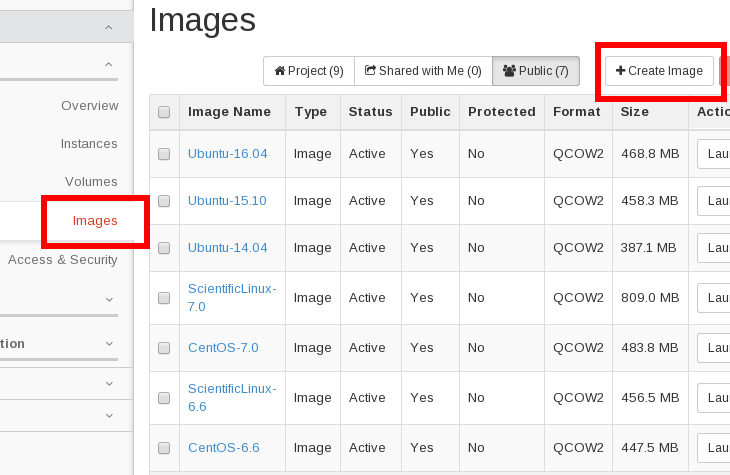
If you prefer to use the web interface instead, you can upload images in the Compute | Images section by clicking the Create Image button:
You will be presented with this dialog:
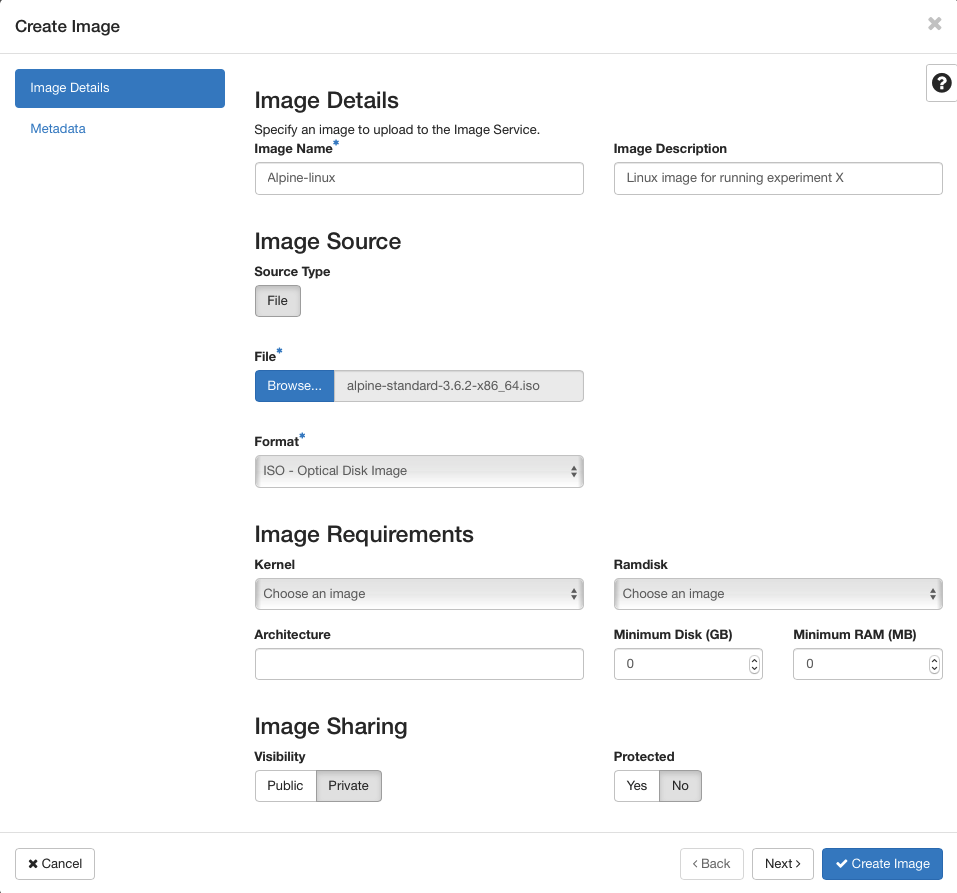
In this dialog, for example, we are creating an image called Alpine-linux. You can optionally add an Image Description for the image, if you need it for your reference. Due to security concerns, we support image uploads only via your local machine, and image upload via public URLs is disabled. In this example, we have thus selected an image we want to upload from our local machine via the Browse button. In this example, our image is an ISO image, so we have selected that in the Format drop-down menu. All remaining fields other than Image Sharing | Visibility can keep their default values. In the Image Sharing | Visibility checkbox, please make sure that you have set the visibility of the image as Private. It is not possible for normal users to create public images due to security reasons. In case you attempt to upload an image and set its visibility as Public, you will get an error message. Setting your image visibility to Private will make your uploaded image private to your particular OpenStack project, and only the members of your project can access it.
Sharing images between Pouta projects
You can share images between different Pouta projects using the command line tools. Image sharing between projects is currently not supported using the Pouta web interface. Once shared, the image will be visible in both projects, i.e. between the donor and acceptor projects.
Please note that image sharing works within the same cloud environment, i.e. you can share images from one cPouta project to another but not between a cPouta project and ePouta project or vice versa.
-
First you need to get the UUID of the image you want to share (
<your-image-UUID>). List all the images in the current project by: -
Secondly you need to get the UUID of the destination project (
<destination-project-UUID>). You can list all your available projects by: -
Once you got the two UUIDs, you need to first make sure the image is of the shared variant if it isn't already:
-
Then, initiate the share by executing the following openstack command in the project of origin:
-
Finally the destination project needs to accept this membership. To do so, you or your colleague needs to execute the following glance command in the acceptor project: