Multi-attach Cinder volumes
Warning
By default the quota is set to 0, you must request it by sending an email to servicedesk@csc.fi
It is possible to attach and mount the same cinder volume into more than one VM at the same time. This means that each of the VMs will be able to read and write to the same block device. This is similar to what a SAN will allow you to achieve.

This feature has several advantages and disadvantages. On one hand it allows to share files among VMs without any kind of intermediary server that you will need with solutions like NFS or GlusterFS. This reduces the number of VMs needed, thus less maintenance and less single points of failure. On the other hand, it is necessary to run what is called a clustered file system like Oracle Cluster File System 2 (ocfs2), or Red Hat Global File System (GFS2). These systems need a cluster of connected daemons that will coordinate the read and write operations of the files. Other file systems like ext4 or xfs do not support this use case and their use might lead to read errors or even data corruption, their use is unadvised. Each VM runs a copy of the daemon and there is no master, but a quorum based system. The choice between the two file systems depends on the use case and preferences based on vendors. In our tests GFS2 seems to be more suitable to Redhat based systems and OCFS2 to Debian ones, but your mileage might vary.
Warning
The configuration, maintenance and operations of these file systems are not a trivial task. The guides below are as a starting point and do not cover all possibilities, for more comprehensive information, please check the upstream documentation.
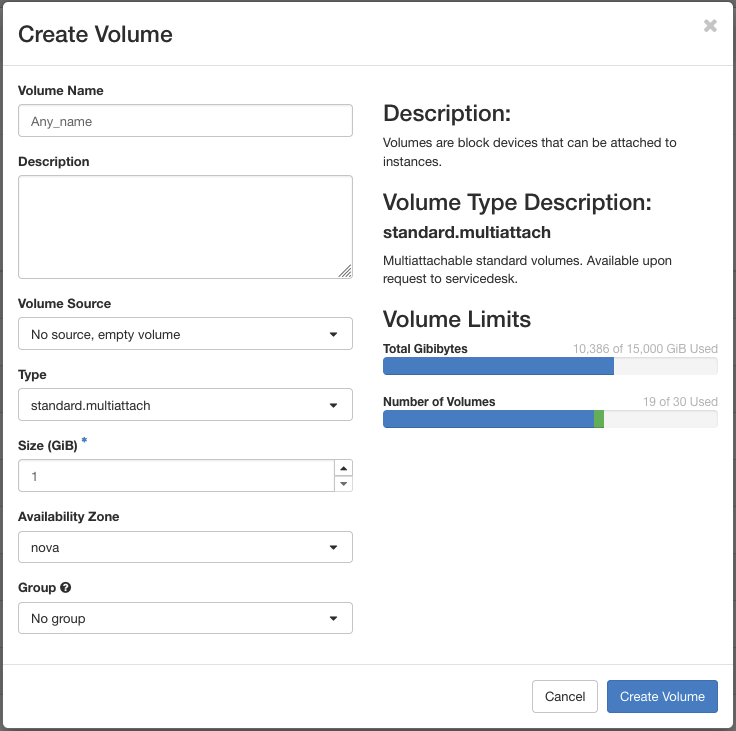
Create and attach a volume
quota
Make sure that you have available quota for this kind of Volume
WebUI
-
Go to the Volume page of Pouta.
-
Click in "+Create Volume"
-
Create a volume as you would do for any other Type of volume. Set the Volume Name and Size (GiB) as desired.
-
Change the Type to
standard.multiattach. -
Click in "Create Volume".
not supported
You cannot attach a volume to multiple VMs from the WebUI, only see its status. You can only attach a volume to multiple VMs using the CLI.
CLI
Before doing this, you need to install the openstack client:
-
Create a multi attach volume:
You need to replace<volume_name>by the name you want to give to the volume, and the<size_in_GB>by the size in Gigabytes you want the volume to have. -
Attach the volume to a VM node:
You need to replace the<volume_name>by the name of the volume you created in the previous step, and the<VM_name>by the name of the VM node. When doing this for a cluster of VMs, you need to run the command once per VM.
GFS2 as an example
The Global file system or (GFS2 in short) is a file system currently developed by Red Hat. It uses dlm to coordinate file system operations among the nodes in the cluster. The actual data is read and written directly to the shared block device.
Warning
GFS2 supports up to 16 nodes connected to the same volume.

GFS2 ansible install
We have written a small ansible cinder-multiattach playbook, that installs a cluster of nodes and installs a shared GFS2 file system on them. The playbook is intended as a guide and demo, it is not production ready. For example, there is a manual step, attach the volume in each node. The Ansible playbook will create a cluster of VMs and install the requested file system on them. The end result will be the same volume mounted in every VM. The quick start commands are these:
$> source ~/Downloads/project_XXXXXXX-openrc.sh
Please enter your OpenStack Password for project project_XXXXXXX as user YYYYYYYY:
$> ansible-playbook main.yml -e fs='gfs2' -e csc_username='johndoe' -e csc_password='easyaccess'
$> for i in $(seq 1 16);
do
openstack --os-compute-api-version 2.60 server add volume "cinder-gfs2-$i" multi-attach-test-gfs2
done
$> ansible-playbook main.yml -e fs='gfs2'
csc_username and csc_password can also be added in the all.yaml file.
It can be a robot account
You need to run Ansible twice due to a bug in the openstack.cloud.server_volume which can only attach the volume to a single VM and fails with the other ones.
If you already have a cluster of VMs, or want to manually create them, it is still possible to use the gfs2 Ansible role. The steps are simple:
-
Create and attach the volume. See the manual Create and attach a volume from above.
-
Create a standard Ansible inventory like this one:
[all] <VM_name> ansible_host=192.168.1.XXX ansible_user=<user> # ... [all:vars] ansible_ssh_common_args='-J <jumphost>'In the example above you need to replace
<VM_name>by the name of the VM, the IP192.168.1.XXXmust be the correct IP of the VM, and finally the<user>has to also be replaced by the corresponding one. You need to have a line per VM node that you want to include in the cluster. Finally, if you are using a Jump Host, you need to replace<jumphost>by its connection information, likeubuntu@177.51.170.99 -
Create a playbook like this one:
--- - name: Configure VMs hosts: all gather_facts: true become: true roles: - role: hosts - role: gfs2This will run two roles, the
hostsone if to create a/etc/hostsfile in every VM with the IPs and names of every VM. Thegfs2role installs and configures the cluster. -
And run it:
GFS2 manual install
In order to install GFS2, you need to follow few steps:
-
Install the VM nodes. There is no special consideration on this step, other than making sure the nodes can see each other in the Network (it is the default behaviour of VM nodes created in the same Pouta project), and that they are installed with the same distribution version. We have tested this with
AlmaLinux-9, other distributions and versions might also work, but we have not tested them. -
Create and attach the volume. See the manual Create and attach a volume from above.
-
For AlmaLinux and other RedHat based distributions you just need enable two collections and install few packages on every node:
Cluster setup
root user
The following commands are executed as the root user
It will be specified throughout this tutorial if the commands must be run on a single or every node.
-
Run the following commands on every node:
-
When you install
pacemaker, it creates a user namedhacluster. You need to set a password to this user: -
Make sure that every node domain name can be resolved in every other node. In Pouta, the simplest way is to use /etc/hosts, where each host has a line similar to:
-
Run the following commands only on one node:
-
You can check the status by running the commands:
By default, corosync and pacemaker services are disabled:
$> pcs status
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
According to pacemaker docs:
requiring a manual start of cluster services gives you the opportunity
to do a post-mortem investigation of a node failure
before returning it to the cluster.
That means, if a node crash and restart, you have to run the command pcs cluster start [<NODENAME> | --all] to start the cluster on it.
You can enable them if you wish with pcs:
$> pcs cluster enable [<NODENAME> | --all]
Fencing setup
root user
The following commands are executed as the root user.
It will be specified throughout this tutorial if the commands must be run on a single or every node.
-
Run the following commands on every node:
-
Since we install
python-openstackclientwith the root user, you must add/usr/local/binin the PATH: -
Create a folder named
openstackin/etc. Then, create a file namedclouds.yamlin/etc/openstack. The YAML file must be like this: -
Run the following commands only on one node:
-
Check the value:
-
Create fencing for the HA cluster. First, you have to determine the UUID for each node in your cluster. You can run the command:
Then:
Substitute$> pcs stonith create <fence_name> fence_openstack pcmk_host_map="node1:node1_UUID;node2:node2_UUID;node3:node3_UUID" power_timeout="240" pcmk_reboot_timeout="480" pcmk_reboot_retries="4" cloud="ha-example"cloud="ha-example"with the name of the cloud you specified in theclouds.yamlfile. -
You can view the available options with the following command:
-
You can test fencing by running these commands:
Tip
If you want to start (or restart) the fence, you can use this command:
Useful if you apply a newclouds.yaml configuration for example.
GFS2 setup
root user
The following commands are executed as the root user.
It will be specified throughout this tutorial if the commands must be run on a single or every node.
-
Run the following command on every node:
-
Run the following commands only on one node:
-
Set up a dlm (Distributed Lock Manager) resource:
-
Clone the resource for the others nodes:
-
Set up a lvmlockd resource part of the locking resource group:
-
Check the status:
-
Still only on one node, create one shared volume groups:
-
On the other nodes, add the shared device to the device file:
-
Start the lock manager:
-
On one node, run:
ClusterName is the name of the cluster (you can retrieve the information with the command$> lvcreate --activate sy -L <size>G -n shared_lv1 shared_vg1 $> mkfs.gfs2 -j <number_of_nodes> -p lock_dlm -t ClusterName:FSName /dev/shared_vg1/shared_lv1pcs status)
FSName is the file system name (i.e: gfs2-demo) -
Create an LVM-activate resource to automatically activate that logical volume on all nodes:
-
Clone the new resource group:
-
Configure ordering constraints to ensure that the locking resource group that includes the dlm and lvmlockd resources starts first:
-
Configure a colocation constraints to ensure that the vg1 resource groups start on the same node as the locking resource group:
-
Verify on the nodes in the cluster that the logical volume is active. There may be a delay of a few seconds:
-
Create a file system resource to automatically mount the GFS2 file system.
Do not add it to the /etc/fstab file because it will be managed as a Pacemaker cluster resource: -
You can verify if the GFS2 file system is mounted:
GFS2 FAQ
-
How to add more nodes?
It is possible to add new nodes to a GFS2 cluster. The supported limit is 16 nodes.
First you need to make sure there are enough journal entries. Use
gfs2_editto get the total number of journals:If it is not enough, you can easily add more with
gfs2_jadd:Secondly, create the new node, install the required software and attach the volume using openstack API. The process is described above.
Then you need to edit the file
/etc/corosync/corosync.confin every node and add an entry for the new one:Once the file is updated, you need to stop the mount and restart the dlm and corosync daemons in every node in the cluster.
Finally, you just need to mount the volume:
-
How to extend my GFS2 volume?
The GFS2 volume was configured using LVM (Logical Volume Manager) that enhances the management and flexibility of physical storage.
a. Create a new multiattach volume and attach it to your instances. Check that the volume is well attached by running the command
sudo parted -lb. On one node, add the new volume in the Volume Group:
c. Still on one node, extend the Logical Volume:
d. Check that the Logical Volume has been extended by running the command
sudo lvse. Before extending the GFS2 volume, check on the other nodes that you don't have error messages. Run
sudo pvs. If you see something like:You must add the device by running the command:WARNING: Couldn't find device with uuid JuoyG2-ftdd-U9xm-LLei-VrY7-4GZz-FgC2dr. WARNING: VG shared_vg1 is missing PV JuoyG2-ftdd-U9xm-LLei-VrY7-4GZz-FgC2dr (last written to /dev/vdX)Check again with the command
sudo pvs. The warning message shouldn't appear.f. If everything's ok, you can grow your GFS2 volume by typing:
Warning
You cannot decrease the size of a GFS2 file system
-
What happens if a VM gets disconnected?
This covers two different use cases, a temporal and/or unexpected disconnection, and a permanent one.
For a temporal and unexpected disconnection, the cluster should be able to deal with this kind of issues automatically. After the node is back, you need to check that all came back to normal. In some cases the automatic mount of the volume can fail, if so mount the volume as explained above.
If it is temporal but expected, like to update the kernel version. Umount the volume in the node before rebooting the node. It is not required, but recommended.
For a permanent disconnection of a VM, one need to do the inverse process of adding a new node. Umount the volume, remove the entry for this VM in the
/etc/corosync/corosync.conffile of every node, and finally restart the daemons in every node. This needs to be done as it affects the quorum count for the cluster. -
Is it possible to mount a node as read-only?
Yes, GFS2 has the "spectator mode":
spectator Mount this filesystem using a special form of read-only mount. The mount does not use one of the filesystem's journals. The node is unable to recover journals for other nodes. norecovery A synonym for spectatorSo, just run this command:
$> pcs resource create sharedfs1 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/shared_vg1/shared_lv1" directory="/mnt/gfs" fstype="gfs2" options=noatime,spectator op monitor interval=10s on-fail=fencefstype="gfs2"is not strictly necessary, as mount can detect the file system type, but it is recommended to avoid mounting the wrong file system. Then double check that the mount went as expected by:
GFS2 Links
- Pacemaker docs
- GFS2 on Amazon EBS Multi-Attach
- Getting start with Pacamaker
- Configuring a Red Hat High Availability cluster on Red Hat OpenStack Platform
- GFS2 file systems in a cluster
- Growing a GFS2 file system
- Managing LVM volume groups
OCFS2 as a second example
The Oracle Cluster File System version 2 is a shared disk file system developed by Oracle Corporation and released under the GNU General Public License. Meanwhile it is a different code base developed by a different vendor. The approach is the same as GFS2:

A single volume attached to a cluster of VM nodes, allowing the data reads and writes to be done directly, and a daemon running in each VM node that coordinates the read and write operations.
OCFS2 ansible install
Like with GFS2, the Ansible playbook will create a cluster of VMs and install the requested file system on them. The end result will be the same volume mounted in every VM. It is very similar than the instructions for GFS2. The quick start commands are these:
$ source ~/Downloads/project_XXXXXXX-openrc.sh
Please enter your OpenStack Password for project project_XXXXXXX as user YYYYYYYY:
$ ansible-playbook main.yml -e fs='ocfs2'
$ for i in $(seq 1 16);
do
openstack --os-compute-api-version 2.60 server add volume "cinder-ocfs2-$i" multi-attach-test-ocfs2
done
$ ansible-playbook main.yml -e fs='ocfs2'
You need to run Ansible twice due to a bug in the openstack.cloud.server_volume which can only attach the volume to a single VM and fails with the other ones.
If you already have a cluster of VMs, or want to manually create them, it is still possible to use the ocfs2 Ansible role. The steps are simple:
-
Create and attach the volume. See the manual Create and attach a volume from above.
-
Create a standard Ansible inventory like this one:
[all] <VM_name> ansible_host=192.168.1.XXX ansible_user=<user> # ... [all:vars] ansible_ssh_common_args='-J <jumphost>'In the example above you need to replace
<VM_name>by the name of the VM, the IP192.168.1.XXXmust be the correct IP of the VM, and finally the<user>has to also be replaced by the corresponding one. You need to have a line per VM node that you want to include in the cluster. Finally, if you are using a Jump Host, you need to replace<jumphost>by its connection information, likeubuntu@177.51.170.99 -
Create a playbook (
main-ocfs2.ymlin this example) like this one:--- - name: Configure VMs hosts: all gather_facts: true become: true roles: - role: hosts - role: ocfs2This will run two roles, the hosts one if to create a
/etc/hostsfile in every VM with the IPs and names of every VM. Theocfs2role installs and configures the cluster. -
And run it:
OCFS2 manual install
In order to install OCFS2, you need to follow few steps:
-
Install the VM nodes. There is no special consideration on this step, other than making sure the nodes can see each other in the Network (it is the default behaviour of VM nodes created in the same Pouta project), and that they are installed with the same distribution version. We have tested this with
Ubuntu v22.04andAlmaLinux-9, other distributions and versions might also work, but we have not tested them. This guide will use Ubuntu as an example.
AlmaLinux requires to install a specific Oracle kernel. More information in the FAQ -
Create and attach the volume. See the manual Create and attach a volume from above.
-
Install the OCFS2 software:
We have tested this with<kernel_version>==6.5.0-21-generic, but newer versions should work as well or better. -
Make sure that every node domain name can be resolved in every other node. In Pouta, the simplest way is to use /etc/hosts, where each host has a line similar to:
-
Enable ocfs2 in every node using:
-
Create the file system. You need to do this in only one of the VM nodes.
Replace
<number_instances>by the number of VM nodes in the cluster. Pay also attention and double check that/dev/vdbis the proper volume name. In principlevdbis going to be the first attached volume to a VM, but this might not be true in all cases. -
Generate the file
/etc/ocfs2/cluster.conf. A minimal working example would follow this template: -
Reboot so the kernel you installed is taken into use. Make sure that the
ocfs2service is up and running (systemctl status ocfs2). -
Finally mount the volume in each node:
As the device may change in any moment, it is recommended to use theUUIDfor any serious deployment. You can get theUUIDby using the commandblkid:In this case the command will be$ sudo blkid /dev/vdb /dev/vdb: UUID="785134b8-4782-4a1f-8f2a-40bbe7b7b5d2" BLOCK_SIZE="4096" TYPE="ocfs2"sudo mount -U 785134b8-4782-4a1f-8f2a-40bbe7b7b5d2 /mnt
OCFS2 FAQ
-
How to add more nodes?
It is possible to add more nodes to a ocfs2 cluster, but it requires a downtime.
First you need to increase the number of slots, using
tunefs.ocfs2. Before that, you need to umount the volume in every VM node. These are the two commands you need to run. The second one only needs to be executed in a single node:Secondly, create the new node, install the required software and attach the volume using openstack API. The process is described above.
Then you need to edit the file
/etc/ocfs2/cluster.confin every node and add an entry for the new one:Replace
<ip_address>by the address of the new server,<vm_name>by its name, and finally<number>is the node id number. It has to be unique for every node, ideally consecutive numbers.Once the file is updated, you need to stop the mount and restart the
ocfs2in every node in the cluster. Lastly, remount the volume in every VM node. -
What happens if a VM gets disconnected?
This covers two different use cases, a temporal and/or unexpected disconnection, and a permanent one. It is very similar to the GFS2 situation.
For a temporal and unexpected disconnection, the cluster should be able to deal with this kind of issues automatically. After the node is back, you need to check that all came back to normal. In some cases the automatic mount of the volume can fail, if so mount the volume as explained above.
If it is temporal but expected, like to update the kernel version. Umount the volume in the node (
sudo umount /mnt) before rebooting the node. It is not required, but recommended.For a permanent disconnection of a VM, one need to do the inverse process of adding a new node. Umount the volume (
sudo umount /mnt), remove the entry for this VM in the/etc/ocfs2/cluster.conffile of every node, and finally restart the daemons in every node. This needs to be done as it affects the quorum count for the cluster. -
Is it possible to mount a node as read-only?
Yes, it is possible to mount the volume as read-only. It is as simple as:
After that, you can check that it was indeed mounted as read-only by:
Also, as you can see in the output above, the default behaviour is that when any error occurs, to remount it as read only (mount | grep /mnt /dev/vdb on /mnt type ocfs2 (ro,relatime,_netdev,heartbeat=local,nointr,data=ordered,errors=remount-ro,atime_quantum=60,coherency=full,user_xattr,acl)errors-remount-ro). Seemount.ocfs2for more options. -
I want to install Oracle Kernel on a RedHat 9 distro
You can find more information here on how to install the Oracle Linux repo. Once set, you can install the Oracle UEK kernel with these commands:
First
And then
Upstream documentation
- GFS2:
- OCFS2: