Copying data between Allas and IDA via Puhti
Copying data from Allas to IDA via Puhti
In order to be able to copy data from Allas to IDA with this procedure, you need to be a member of a project which has IDA and Puhti services in use. On the Allas side, you need at least read access to the data. You either need to be a member of a project which has Allas service in use, or the data in question needs to be available for downloading in Allas. Note that the projects in Allas, Puhti and IDA do not need to be the same.
In short, there are four steps to follow:
- Download the data from Allas to Puhti scratch disk
- Rearrange the data on the scratch disk
- Upload the data to IDA
- Clean the Puhti scratch disk
Note
Data in IDA is required to be described as research datasets with Fairdata services. See more information here.
Step 1. Download the data from Allas to Puhti scratch
Scratch disk area in Puhti is recommended as it is by default much larger than other areas, e.g. user's home folder. Also, you can request even larger scratch quota if the default is not enough. On Puhti, you can show the available disk areas and their usage with command:
For more details about Puhti disk areas, see Supercomputer disk areas.
For example, create a new directory copydir for the data under the scratch
area of project_2000013 (replace this with your own project ID):
Download the data from Allas to that new directory. You should use the same protocol as was used to originally upload the data to Allas. If the data was uploaded with command-line tools, preferably also use the same command-line tool. More information about the Allas tools on Puhti is available at Accessing Allas in the CSC computing environment and other Linux platforms.
In our example case the data was originally uploaded to Allas with a-commands,
so the user uses a-get to download the data:
module load allas
allas-conf
cd /scratch/project_2000013/copydir
a-get 2000013-wrk-bucket/working_data.tar.zst
a-get command downloads the data and extracts it into the copydir
directory.
Step 2. Rearrange the data on scratch
This is an important step when copying data from Allas to IDA. You should only copy data that is important enough to be described as a dataset in Fairdata services. Also, it makes the rest of the procedure easier to think at this point what kind of a directory structure would be good for the datasets and arrange the data in the Puhti directory to follow that structure. Note that in IDA you can't freeze (turn stable research data to an immutable state) more than 5000 files at once. So, as a rule of thumb, you should have at most that amount of files in one directory.
In case you will include some files in more than one dataset, do not make duplicate files – IDA files may belong to multiple datasets.
In our example case, the project decides that it makes sense to have two
distinct datasets, so the data is rearranged into two directories,
experiment_a and survey_2021.
Step 3. Upload the data to IDA
You should only copy data that is important enough to be described as datasets in Fairdata services. Also, you should have the data already rearranged into a directory structure that would be good for the datasets.
You can upload the data using the IDA command-line tool, which uses the syntax:
Continuing our example, uploading both directories (experiment_a and
survey_2021) to IDA project 2000002:
module load ida
cd /scratch/project_2000013/copydir
ida upload -p 2000002 experiment_a experiment_a
ida upload -p 2000002 survey_2021 survey_2021
More examples can be found in the GitHub repository of the IDA command-line tool.
If the user has already configured the IDA command-line tool, then the upload command uses that configuration. If not, then the upload command asks the user for their username and password in IDA. See detailed instructions here.
Step 4. Clean the Puhti scratch
If you do not need to continue working with the data on Puhti after uploading it to IDA, remove it from the scratch disk area of Puhti to free up disk space.
Copying data from IDA to Allas via Puhti
In order to copy data from IDA to Allas, you need to be a member of a project that has Allas and Puhti services in use. On the IDA side, you either need to be a member of a project which has IDA service in use, or the data in question needs to be publicly available for downloading. Note that the projects in Allas, Puhti and IDA do not need to be the same.
Automatic copying with ida2allas tool
If you wish to move a complete directory from IDA to Allas object storage service without any changes or rearrangements, you can use command line tool ida2allas. This tool is available in Puhti server at CSC.
1. Connect to Puhti
We recommend that you run the data transfer process in one of the login nodes of the Puhti. (Login nodes can be used in this case as the data transfer process is not computationally heavy). The easiest way to open a login node session in Puhti is to use the WWW interface of Puhti:
In the web interface, choose Login node shell from the Tools menu. This opens a terminal session where you can set up connections to IDA and Allas and where you can execute the data transport process.
2. Establishing connections
First, open the Allas connection using the S3 protocol with the following commands:
The allas-conf command will prompt you to enter your CSC password. The Haka password is not accepted. After that you will choose the Allas project where the data will be copied.
Next, establish the IDA connection with the commands:
The configuration process will ask for your IDA project number and app password that you can get from IDA web interface.
If you already have a working IDA connection configured, you can choose not to overwrite the .ida-config and .netrc files. In that case, you won’t need to retrieve a new IDA key from the web interface.
3. Data transfer
Data transfer is launched with the command:
The program will first ask whether to fetch data from the IDA staging area or the frozen area.
Then it will list the folders in the selected IDA area and prompt you to choose the folder to transfer.
Finally, the program will list the buckets (storage folders) in Allas and ask you to select the one where you want to transfer the data. You can also create a new bucket. Do not use uppercase letters, spaces, or special characters in the name of the bucket. Further, note that bucket names must be unique compared to any Allas project. Thus it is a good habit to add some project specific part to the bucket name.
In case of large (over 100 GiB) data transfers you can start the transfer with the commands:
In the example above, screen command launches a virtual terminal session where the ida2allas command will continue running even if the connection to Puhti would be lost.
Manual data transfer from IDA to Allas
If you don't want to copy a complete IDA directory to Allas or if you want to rearrange the data, then you need to do the data transfer in four steps:
- Download the data from IDA to Puhti scratch disk
- Rearrange the data on the scratch disk, if necessary
- Upload the data to Allas
- Clean the Puhti scratch disk
Step 1. Download the data from IDA to Puhti scratch
Scratch disk area in Puhti is recommended as it is by default much larger than other areas, e.g. user's home folder. Also, you can request even larger scratch quota if the default is not enough. For more details about Puhti disk areas, see Supercomputer disk areas.
For example, create a new directory xferdir for the data under the scratch
area of project_2000012 (replace this with your own project ID):
If the data to be downloaded from IDA is in a project the user belongs to, then downloading the data from IDA can be done with the IDA command-line tool:
Continuing our example, if the data in IDA is in a directory testi of project
2000001, the download commands to run on Puhti are:
The last argument of the ida download command is the file name given to the
data on Puhti. As in this case a directory is downloaded, it will be downloaded
as a zip package. If the user has used and configured the IDA command-line
tool previously, then the download command uses that configuration. If not,
then the upload command asks the user for their username and password in IDA.
See detailed instructions here.
If the data to be downloaded from IDA is a published open dataset visible in Fairdata Etsin, then downloading it requires two steps; locating and copying the download command in Etsin, and then downloading the dataset. The download button in Etsin has an option to show download commands for a few command-line tools.
Again continuing our example, the user selects a dataset directory for downloading in Etsin. After a while, the zip package is ready, and Etsin shows the download button:
User clicks the option menu of the download button to see the command-line options:
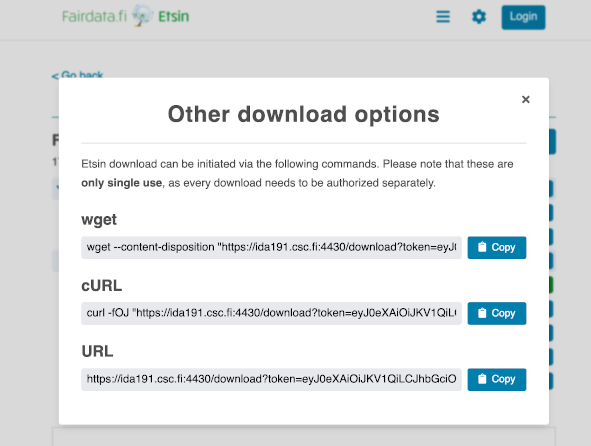
The user could then, for example, copy the curl command and run it on Puhti:
cd /scratch/project_2000012/xferdir
curl -fOJ "https://ida191.csc.fi:4430/download?token=18f6e5b7edae4f12a8a654ea22d57aa9.PA0p5PMqnzvgcXAU0Lw9SuVcyoQGgV8Ugnk3GEppU0b4UUhGWRLP8FRHB2MvyUTjPA0p5PMqnzvgcXAU0Lw9SuVcyoQGgV8Ugnk3GEppU0b4UUhGWRLP8FRHB2MvyUTjPA0p5PMqnzvgcXAU0Lw9SuVcyoQGgV8Ugnk3G_e3668097e34d437484e15d53624e7905=76679a7a-367c-474f-9e8c-c3869a106e2f_ehr3hd76&package=76679a7a-367c-474f-9e8c-c3869a106e2f_ehr3hd76.zip"
Step 2. Rearrange the data on scratch, if necessary
In case you would like to rearrange the data or remove parts of it, you can do it on the scratch disk before you upload it to Allas.
Continuing our example, once the data is downloaded as testi.zip (or
76679a7a-367c-474f-9e8c-c3869a106e2f_ehr3hd76.zip in case of an open dataset)
in the project's scratch area, the package can simply be extracted with unzip:
Step 3. Upload the data to Allas
The easiest way to upload the data to Allas is using the a-put command.
a-put uploads a directory as one archived object to Allas. It needs enough
space in the working directory to create the archive to upload, so the current
working directory should be on the scratch disk. The basic syntax of the
a-put command is:
More information about the Allas tools on Puhti is available at Accessing Allas in the CSC computing environment and other Linux platforms.
Continuing our example, assuming the unzipped data to be uploaded to Allas is
in a directory experiment_data, it can be uploaded with a-put as:
Step 4. Clean the Puhti scratch
If you do not need to continue working with the data on Puhti after uploading it to Allas, remove it from the scratch disk area of Puhti to free up disk space.